LLM
Refs
What is a language model?
Simple terms
- A language model is a system that understands and predicts human language. It learns patterns and relationships between words and uses that knowledge to generate coherent and meaningful text.
Technical terms
- A language model refers to a probability distribution over text.
P(‘Today is a sunny day.’)- The goal of a language model is to assign higher probabilities to more fluent and coherent sequences while assigning lower probabilities to less likely or nonsensical combinations of words.
P(‘Today is a sunny day.’)=0.9P(‘Sunny today is a day.’)=0.1
How to train a language model?
- Ask Claude.ai for a detailed explanation
Data Collection
The first step is to gather a massive dataset of text data, often from sources like books, websites, and social media. This provides the raw text that the model will learn from.
Text Preprocessing
The collected text data is then preprocessed - this includes steps like removing formatting, converting to lowercase, handling punctuation, etc. This cleaning process prepares the data for training.
Model Architecture: A neural network architecture is designed for the model. This defines how the model will process input text and make predictions. Common architectures include transformers, CNNs, RNNs/LSTMs.
Parameter Initialization
The model starts with random initialized parameters. These are the internal weights that will be tuned during training.
Training
The preprocessed text is fed through the model in small batches. The predictions are compared to the actual text to calculate an error signal through a loss function. This error is then propagated back through the model using optimization techniques like gradient descent to update the parameters and minimize the loss.
Repeat
The training dataset is looped through many times as the model incrementally improves and learns the statistical relationships between words/tokens. More passes through the data result in better tuning of the parameters.
Evaluation: During training, the model’s performance is evaluated on a validation set to monitor progress. Training stops when validation performance stops improving.
Use
Once trained, the optimized model can generate predictions on new text input, usually by predicting the next word in a sequence. The trained parameters encode the linguistic patterns discovered from the training data.
How large is a large language model?
A large language model refers to a specific type of language model that is characterized by its size, capacity, and ability to comprehend and generate human language at an unfathomable scale.
As discussed above, LLMs are built using deep learning techniques, particularly leveraging Transformer architecture. These models are trained on massive amounts of text data, often encompassing billions or even trillions of words.
That’s where the word “large” comes from in a “large language model”. This includes both the size and complexity of the neural network as well as the size of the dataset it was trained on.
Transformers
Transformers are a type of neural network architecture that allows LLMs to process sequential data, such as text, parallelly by considering the context and dependencies between words or tokens.
Unlike traditional recurrent neural networks (RNNs) that process sequential data step-by-step, Transformers leverage a mechanism called self-attention to capture the dependencies between different positions in the input sequence.
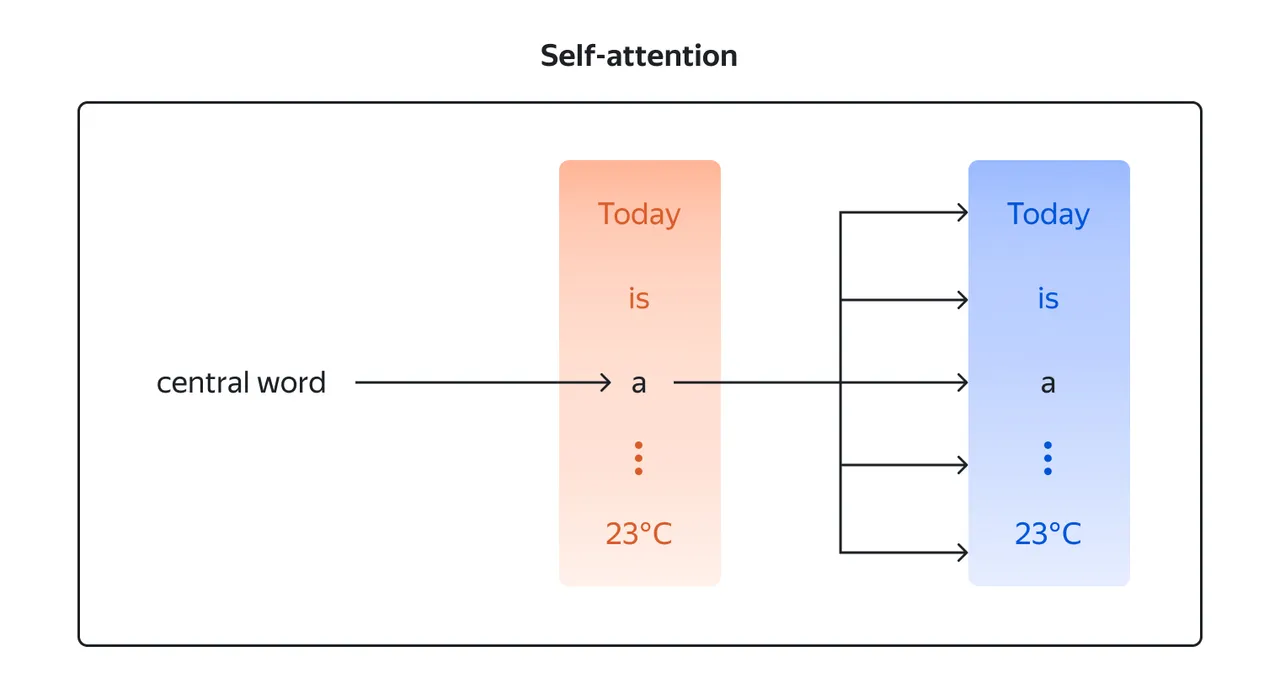
This allows them to consider the entire context simultaneously, rather than relying on the sequential processing of data.
The parallelization capabilities of Transformers allow us to scale them effectively and train them on massive text datasets.
Embeddings
Embeddings are dense vector representations of words or tokens that capture semantic meaning. Each word is assigned a unique vector like [0.1, 0.3, 0.2, …] in a high-dimensional space.
Here is a simple example to illustrate how word embeddings work:
Let’s say we have a vocabulary of 4 words: {cat, dog, apple, banana}.
We want to encode each word into a 3-dimensional embedding vector (just to keep it simple).
After training on large amounts of text data, the model learns the following embeddings:
1 | cat = [0.1, 0.5, 0.3] |
Notice how the vectors for cat and dog are closer together in the embedding space compared to apple and banana. This is because cat and dog are semantically similar concepts, while apple and banana are more distant.
The distances between all the embedding vectors encode the semantic relationships between the words, which is learned by the model through analyzing word usage patterns in the training data.
Prompt
- A prompt is a starting input that is provided to a language model to generate a response or complete a text.
Zero-shot learning & Few-shot learning
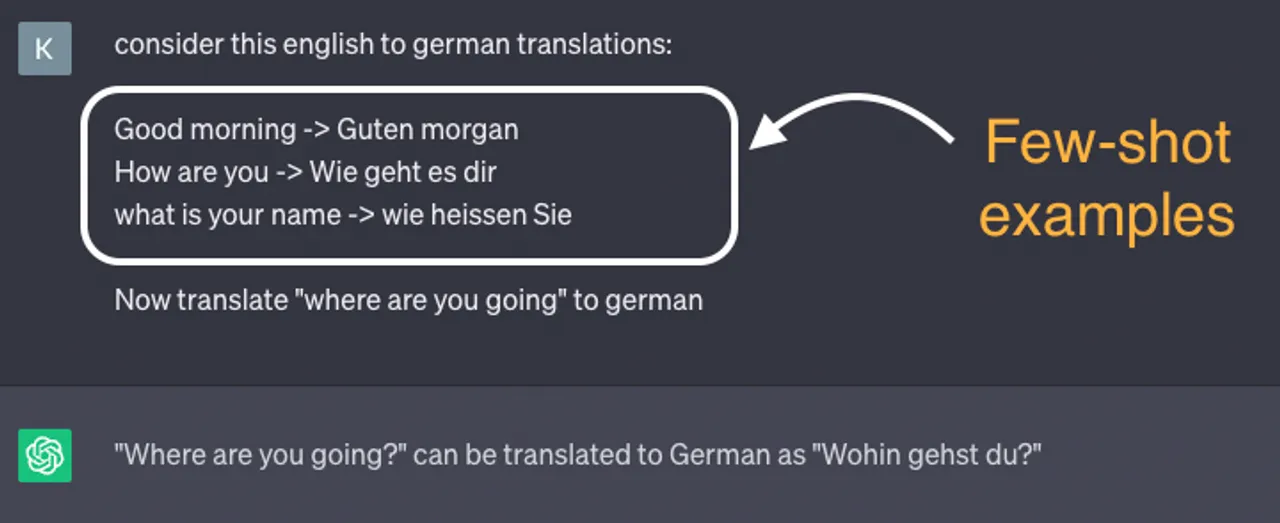
- zero-shot learning allows the LLM to generate responses or perform specific tasks solely from the instructions in the prompt, without any fine-tuning.
- Essentially, by exposing the model to a limited number of task-specific examples in its prompt, it can quickly learn to generate responses or perform tasks with a higher degree of accuracy and fluency.
How to train a large language model?
Training LLMs is a computationally intensive process that involves two main steps:
- pre-training
- fine-tuning
Pre-training
- During pre-training, the model is exposed to a massive corpus of unlabeled text data, often gathered from the internet.
- This unlabeled data serves as the foundation for the model to learn the statistical patterns, semantic relationships, and linguistic structures present in human language. The objective is to enable the model to predict missing words or generate coherent sentences, effectively capturing the statistical patterns in the language.
- Pre-training typically involves the use of a language modeling objective, such as masked language modeling or predicting the next word (or sentence) in a sequence.
- After pre-training, the model learns a rich representation of language and acquires knowledge about various linguistic aspects.
- However, this pre-trained model still needs to be tweaked to perform specific tasks effectively. That’s where the fine-tuning comes in.
Fine-tuning
The word “fine” in fine-tuning refers to making small, fine adjustments to the model parameters and representations. Here’s a bit more explanation:
Compared to pre-training from scratch, the changes made during fine-tuning are small and focused.
Only the highest model layers tend to get updated during fine-tuning. The low-level feature representations remain mostly fixed.
The learning rate used for fine-tuning is much lower, like 1/10th or 1/100th of pre-training rates. This results in slow, smooth updates.
The number of training epochs is also typically low for fine-tuning, e.g. 3-10 epochs versus hundreds of epochs for pre-training.
These constraints prevent overwriting the pre-trained knowledge which could lead to catastrophic forgetting.
The updates gently tune the model’s weights to adapt it to the new task using the pre-trained knowledge.
It’s like making fine adjustments to a nearly complete painting rather than starting with a blank canvas.
The final performance gains from fine-tuning are often small but significant, e.g. 1-3% above pre-training.
So in essence, “fine” refers to the delicate nature of the changes during fine-tuning to retain existing learning and make focused improvements. It fine-tunes the model without overhauling it completely.
Key benefits
Task-Specific performance boost: LLMs, through fine-tuning, can leverage task-specific labeled data to improve their performance. The model can learn to make more accurate predictions and generate contextually appropriate responses tailored to the target task.
Flexibility and customization: LLM fine-tuning offers flexibility to customize the model’s behavior and responses according to specific requirements. By fine-tuning, one can guide the model’s learning process and shape its output to align with desired behaviors and guidelines.
Incremental learning: Fine-tuning allows LLMs to be continuously improved over time. As new labeled data becomes available, the model can be fine-tuned iteratively to incorporate the latest information and adapt to changing needs.
Computational efficiency: Fine-tuning reduces the computational burden compared to training a large model from scratch. Pretraining the LLM on large-scale data can be a time-consuming and resource-intensive process. However, once the LLM is pretrained, fine-tuning is a much faster process.
How to perform fine-tuning
Update the knowledge of the LLM
- For example, fine-tune a model on medical literature or a new language
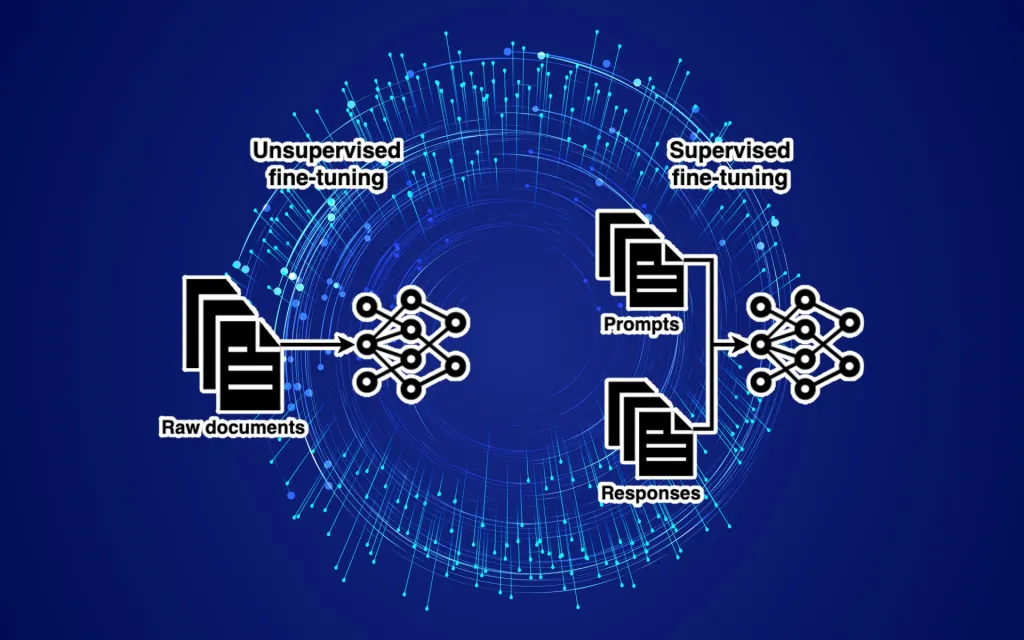
- Use an unstructured dataset, such as articles and scientific papers
- The advantages of unstructured data is that it is scalable as models can be trained through unsupervised or self-supervised learning
- However, in some cases, updating the knowledge is not enough and you want to modify the behavior of the LLM
- SFT(Supervised Fine-tuning) is employed
- SFT is a collection of prompts and their corresponding responses
- SFT is especially important for LLMs like LLMs like ChatGPT, which have been designed to follow user instructions and stay on a specific task across long stretches of text
- Also referred to as Instruction Fine-tuning
- RLHF: Reinforcement Learning from Human Feedback: SFT to the next level
- Brings humans in the loop to steer the LLM in the right direction
- Human reviewers rate the output of the model on prompts
PEFT: Parameter-efficient Fine-tuning
- PEFT aims to reduce the number of parameters that need to be updated in the process of fine-tuning
- LoRA: Low-rank Adaptation
- The idea behind LoRA is that fine-tuning a foundation model on a downstream task does not require updating all of its parameters. There is a low-dimension matrix that can represent the space of the downstream task with very high accuracy.
- PTuning
- A PEFT method introduced by THUDM, current at v2
- Other methods
- See huggingface supported methods
- LoRA, Prefix Tuning, P-Tuning, Prompt Tuning, AdaLoRA, LLaMA-Adapter, IA3…